本篇目录:
- 1、文章的分页用存储过程怎么写?
- 2、SQL语句分页查询,一页面多少数据合适
- 3、sql存储过程定义多条件查询加分页
- 4、如何通用存储过程来对MySQL分页查询进行操作
- 5、SQL如何实现数据分页,要具体语句,谢谢
- 6、SQL分页与存储过程分页是一样的吗
文章的分页用存储过程怎么写?
分页方案一:(利用Not In和SELECT TOP分页) 效率次之,需要拼接SQL语句 分页方案三:(利用SQL的游标存储过程分页) 效率最差,但是最为通用 在实际情况中,要具体分析。
干嘛用存储过程去分页,如果是在ASP.NET中只用设置显示数据的控件具有分页功能就行了。
-图1")
事实果真是这样吗?这三种方案就是比DataGrid 控件的内置分页功能好吗?我以前用Access做程序时发现Not in语句效率很低的呀?于是决定亲自试一试。装SQL有点麻烦,就用 Access 吧,方案一用存储过程分页没有试验。
select from (select a.*,rownum r from (select from table_a)a where rownum=b)where r=a 该sql语句实现了分页查询。
在sp_Paginate存储过程中用了一个fn_CreateCondition函数, 它是用来把要查询的字符分解(查询的字符可以用空格分开,表示多关键字查询)后,返回一个可用的(如果查询的字符为空,那么返回一个真条件)WHERE条件。
SQL语句分页查询,一页面多少数据合适
每个页面调用10条左右的SQL,数量上偏多(不太复杂页面建议5个以下),不过还是要看页面的复杂度和页面响应时间。建议合并sql(用一些子查询、多层嵌套查询等),毕竟每一次查询就要耗一次IO读写等待时间。
-图2")
sql中的10表示你每页显示的数据,这里跟10,就代表每页显示10条。(你可以定义一个常量作为每页显示的条数)where中的20表示不包括前面的20条数据,也就是查询出从第21条到30之间的数据。
首先preparedstatement是statement的子接口,属于预处理操作,与直接使用statement不同的是,preparedstatement在操作的时候,先在数据表中准备好了一条sql语句,但是sql语句的值暂时不设置,而是之后设置。
sql存储过程定义多条件查询加分页
(1)、将全部数据先查询到内存中,然后在内存中进行分页,这种方式对内存占用较大,必须限制一次查询的数据量。
select top 5 id,readcount,weight from table1 order by readcount desc union all select top 10,id,readcount,weight from table1 order by weight desc --这句进行动态sql或传参数进行分页,网上分页的sql很多。
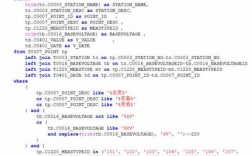
-图3")
//分页函数//定义函数pageft(),三个参数的含义为://$totle:信息总数;//$displaypg:每页显示信息数,这里设置为默认是20;//$url:分页导航中的链接,除了加入不同的查询信息“page”外的部分都与这个URL相同。
EXEC (@SQLSTR)以上存储过程对页数进行判断,如果是第一页或最后一页,进行特殊处理。其他情况使用2次TOP翻转。其中排序条件为ProductID倒序。最后通过EXECUTE执行SQL字符串拼串。
下面简单讨论一下多表联合的情况。对于最常见的等值表连接查询,CBO 一般可能会采用两种连接方式NESTED LOOP和HASH JOIN(MERGE JOIN效率比HASH JOIN效率低,一般CBO不会考虑)。
以下的文章主要描述的是通用存储过程来对MySQL分页查询进行正确的操作,你如果对MySQL分页查询进行正确的操作有兴趣的话你就可以点击以下的文章进行观看了。望你浏览之后能有所收获。
如何通用存储过程来对MySQL分页查询进行操作
1、建议:如果是商品 字段却很长,表占用空间很大,检索表的时候需要执行大量的IO,严重降性能。这时需要把大的字段拆分到另一个表,并且该表与原表是一对一的关系。
2、其威力和优势主要体现在:存储过程只在创造时进行编译,以后每次执行存储过程都不需再重新编译,而一般 SQL语句每执行一次就编译一次,所以使用存储过程可提高数据库执行速度。
3、(1)、将全部数据先查询到内存中,然后在内存中进行分页,这种方式对内存占用较大,必须限制一次查询的数据量。
4、使用redis维护一个主键序列,分页操作就是截取该序列的一部分,其结果就是主键id集合。拿到id后便可以映射到多台mysql服务器上查询数据了。
SQL如何实现数据分页,要具体语句,谢谢
1、最后,找到函数GetArcList方法,然后添加一个方法,通过传入sql参数可以获得指定的数据源。
2、几种典型的分页sql,下面例子是每页50条,198*50=9900,取第199页数据。
3、首先我们建立一个表表的数据,这个表里有25条数据,id从1到25。(下图是部分截图)要分页数据,首先我们假设一页有10条数据,我们可以用mysql的 limit关键字来限定返回多少条数据。
4、就代表每页显示10条。(你可以定义一个常量作为每页显示的条数)where中的20表示不包括前面的20条数据,也就是查询出从第21条到30之间的数据。不知道我这样说你是否理解,其实只要理解了sql语句,分页就很好做了。
SQL分页与存储过程分页是一样的吗
1、存储过程 和一般sql的区别就是,存储过程支持变量和判断循环之类的,你可以把一个存储过程想象为一个小的软件,这个小软件帮你处理一些复杂的sql运算。
2、用存储过程是每一次只获得当前页的数据,也就是一页显示过少条记录就从数据库中取得多少条记录。如果是用java,如果数据量不是很大,可以把所有的数据记录全部取出来,然后只显示这一页要显示的记录。这就是所谓的假分页。
3、程序级分页也叫做内存分页,就是将所有数据(注意是所有数据)取出来作为一个 数据集 放在内存中,然后我们对这个数据集进行分页就数据程序级的分页。
4、以上存储过程是使用2005的TOP (表达式) 新功能,避免了字符串拼串,使结构化查询语言变得简洁。实现的为同样的功能。
5、sql 2000的话,可以将数据选出来放入一个临时表,临时表加一个自增长得字段 然后根据这个数字,自己就可以控制一页多少条记录了 方法如上,是我自己工作中使用检验过,有效的。
6、分页方案一:(利用Not In和SELECT TOP分页) 效率次之,需要拼接SQL语句 分页方案三:(利用SQL的游标存储过程分页) 效率最差,但是最为通用 在实际情况中,要具体分析。
到此,以上就是小编对于mysql中分页用到的语句是的问题就介绍到这了,希望介绍的几点解答对大家有用,有任何问题和不懂的,欢迎各位老师在评论区讨论,给我留言。
 微信扫一扫打赏
微信扫一扫打赏