本篇目录:
K-means原理、优化、应用
在 K-means 算法中,首先需要根据初始聚类中心来确定一个初始划分,然后对初始划分进行优化。
)在K-means算法中,首先需要根据初始聚类中心来确定一个初始划分,然后对初始划分进行优化。
-图1")
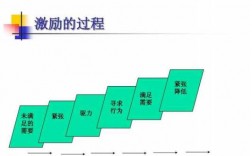
K-means算法是一种常用的聚类算法,其原理如下:初始化:随机选择k个初始质心,每个质心表示一个簇的中心点。分配:对于每个数据点,计算其到k个质心的距离,将其分配给距离最近的质心所表示的簇。
K-MEANS算法的处理流程
1、重复步骤2和步骤3,直到满足某个停止准则,例如簇中心不再发生变化,簇内平方和达到最小值,或达到预定的迭代次数。输出:算法输出K个簇及其对应的簇中心。
2、选择K个初始聚类中心点,可以随机选择或根据实际需求选择。 将所有数据点分配到距离它们最近的聚类中心点所在的簇中。 重新计算每个簇的中心点。 重复步骤2和3,直到簇中心点不再变化或达到最大迭代次数。
3、把所有数据归好集合后,一共有k个集合。然后重新计算每个集合的质心。
-图2")
聚类分析:k-means和层次聚类
1、聚类分析算法很多,比较经典的有 k-means 和 层次聚类法 。k-means的k就是最终聚集的簇数,这个要你事先自己指定。
2、kmeans是K均值聚类 cluster是层次聚类 从总体思想上k均值是由上到下的,他是在你给定所分的类数后,保证这K类之间获得最大的划分。
3、聚类分析有两种主要计算方法,分别是凝聚层次聚类(Agglomerative hierarchical method)和K均值聚类(K-Means)(1)层次聚类首先要定义样本之间的距离关系,距离较近的归为一类,较远的则属于不同的类。
4、动态聚类k-means 层次聚类,在类形成之后就不再改变。而且数据比较大的时候更占内存。 动态聚类,先抽几个点,把周围的点聚集起来。然后算每个类的重心或平均值什么的,以算出来的结果为分类点,不断的重复。直到分类的结果收敛为止。
-图3")
5、典型的聚类算法有:K-means算法:将n个数据点分成k个簇,每个数据点属于距其最近的簇,簇的中心点通过所有点的均值计算得到。层次聚类算法:通过不断合并或分裂簇来建立聚类树,包括凝聚层次聚类和分裂层次聚类两种方法。
如何检测数据变异大小差异的统计
1、将每个年份的数据分别计算出平均值和标准差。 根据公式计算出每个年份的变异系数,即将标准差除以平均值。
2、最直接也是最简单的方法,即最大值-最小值(也就是极差)来评价一组数据的离散度。这一方法在日常生活中最为常见,比如比赛中去掉最高最低分就是极差的具体应用。极差=最大标志值—最小标志值。
3、标准差的计算方法是先求出每个数据值与平均值之差的平方,然后将这些平方值相加并除以数据个数,最后取平方根得到标准差。
4、t检验 t检验就是检验统计量为t的假设检验。 用于检验两个变量之间的差异。假设检验的一般步骤: ? 根据实际问题提出原假设H0与备择假设 H1。 ? 选择统计量t作为检验统计量,并在H0成立的条件下确定t的 分布。
到此,以上就是小编对于MEANS过程中方差的统计量关键字为的问题就介绍到这了,希望介绍的几点解答对大家有用,有任何问题和不懂的,欢迎各位老师在评论区讨论,给我留言。
 微信扫一扫打赏
微信扫一扫打赏