本篇目录:
mongoDB主要使用在什么场景?
1、MongoDB适用于需要处理大量数据,特别是无结构或半结构化数据的场景,同时需要高性能和水平扩展能力的应用场景。 处理大量数据:MongoDB是一个面向文档的数据库,采用BSON(二进制JSON)格式存储数据。
2、(4)高伸缩性的场景:MongoDB适合由数十或数百台服务器组成的数据库。(5)用于对象及JSON数据的存储:MongoDB的BSON数据格式适合文档化格式的存储及查询。mongodb设计特点:(1)面向集合存储,容易存储对象类型的数据。
-图1")
3、● 物流场景:使用MongoDB存储订单信息,订单状态在运送过程中会不断更新,以MongoDB内嵌数组的形式来存储,一次查询就能将订单所有的变更读取出来。
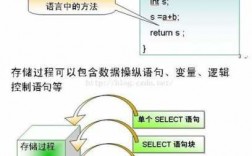
mongoDB应用篇-mongo聚合查询
如果我们在日常操作中,将部分数据存储在了MongoDB中,但是有需求要求我们将存储进去的文档数据,按照一定的条件进行查询过滤,得到想要的结果便于二次利用,那么我们就可以尝试使用MongoDB的聚合框架。
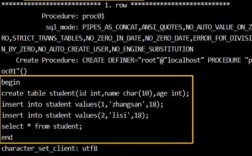
之前也说过,MongoDB数据库里面的数据是键值对形式,所以如果想要插入多条数据,可以这样写,也就是键值对之间用逗号隔开。如果想要查询数据,则可以使用db.集合名.find()语句来查询。
MongoDB适用于需要处理大量数据,特别是无结构或半结构化数据的场景,同时需要高性能和水平扩展能力的应用场景。 处理大量数据:MongoDB是一个面向文档的数据库,采用BSON(二进制JSON)格式存储数据。
-图2")
使用场景:(1)网站数据:MongoDB适合实时的插入,更新与查询,并具备网站实时数据存储所需的复制及高度伸缩性。(2)缓存:由于性能很高,MongoDB也适合作为信息基础设施的缓存层。
在上一篇 mongodb Aggregation聚合操作之$unwind 中详细介绍了mongodb聚合操作中的$unwind使用以及参数细节。本篇将开始介绍Aggregation聚合操作中的$count操作。说明:查询展示文档数量的总数。
在MongoDB存储的文档上执行聚合操作非常有用,这种方式的一个限制是聚合函数(比如,SUM、AVG、MIN、MAX)需要通过mapper和reducer函数来定制化实现。MongoDB没有原生态的用户自定义函数(UDFs)支持。
如何把mongodb中的数据读到内存中
如果有服务器重启了,它就可以从同一个副本集中另外一个服务器中读取数据从而重建自己的数据(重新同步,resync)。
-图3")
方式一:使用tmpfs作为文件系统 方式二:使用ramfs作为文件系统 这两种方式的思路都差不多,使用一个内存模拟文件系统,由于替换了磁盘文件系统,数据就保留在内存中。
mongodb的数据是存储在硬盘上的,只不过需要经常读取的数据会被加载到内存中,这样提高查询效率,所谓内存数据映射,所以mongodb本身很吃内存,不过0版本以后会好很多。
将MongoDB设置成Windows服务 这个操作就是为了方便,每次开机MongoDB就自动启动了。首先在解压后的MongoDB文件夹里面建立data和logs两个目录,看名字就知道,data存放数据,logs存放日志文件。
到此,以上就是小编对于mongodb 存储数据 结构的问题就介绍到这了,希望介绍的几点解答对大家有用,有任何问题和不懂的,欢迎各位老师在评论区讨论,给我留言。
 微信扫一扫打赏
微信扫一扫打赏