本篇目录:
- 1、mapreduce和hadoop难吗
- 2、Hadoop从入门到精通33:MapReduce核心原理之Shuffle过程分析
- 3、Hadoop:是什么,如何工作,可以用来做什么
- 4、请简要描述Hadoop计算框架MapReduce的工作原理
mapreduce和hadoop难吗
1、根据数据分片信息中的个数确定map task的个数,然后为每个map task生成一个TaskInProgress对象来处理数据分片,先将其放入nonRunningMapCache,以便JobTracker分配任务的时候使用。
2、复杂性:hadoop和mapreduce需要一些专业知识和技能,因此对于不熟悉这些技术的人来说,学习和使用它们可能比较困难。
-图1")
3、hadoop是依据mapreduce的原理,用Java语言实现的分布式处理机制。
4、除了上述这几个方面,我们还需要了解hadoop的单机模式、伪分布模式和分布式模式的搭建方式。
5、Hadoop是用来开发分布式程序的架构,是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。MapReduce是用来做大规模并行数据处理的数据模型。
Hadoop从入门到精通33:MapReduce核心原理之Shuffle过程分析
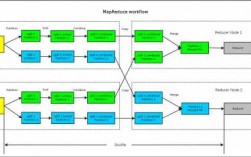
从运算效率的出发点,map输出结果优先存储在map节点的内存中。
-图2")
Map端的Shuffle过程到此结束。 Reduce任务拖取某个Map对应的数据,如果在内存中能放得下这次数据的话就直接把数据写到内存中。
主要思想:Hadoop中的MapReduce是一种编程模型,其核心思想是将大规模数据处理任务分解为两个主要阶段:Map阶段和Reduce阶段。详细解释 Map阶段 在Map阶段,输入数据被分割成若干小块(splits),然后由一个Map函数处理。
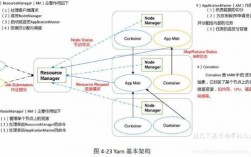
Hadoop 0即第二代Hadoop系统,其框架最核心的设计是HDFS、MapReduce和YARN。其中,HDFS为海量数据提供存储,MapReduce用于分布式计算,YARN用于进行资源管理。
MapReduce里的Shuffle:描述着数据从map task输出到reduce task输入的这段过程。 Map端流程分析 1 每个输入分片会让一个map任务来处理,默认情况下,以HDFS的一个块的大小(默认64M)为一个分片,当然我们也可以设置块的大小。
-图3")
Hadoop:是什么,如何工作,可以用来做什么
Hadoop是用来开发分布式程序的。Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
接收client用户的操作请求,这种用户主要指的是开发工程师的Java代码或者是命令客户端操作。维护文件系统的目录结构,主要就是大量数据的关系以及位置信息等。
Hadoop是用来开发分布式程序的架构,是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。MapReduce是用来做大规模并行数据处理的数据模型。
hadoop是什么意思?Hadoop是具体的开源框架,是工具,用来做海量数据的存储和计算的。
请简要描述Hadoop计算框架MapReduce的工作原理
分为2个步骤,map和reduce,map专门负责对每个数据独立地同时地打标签,框架会对相同标签的数据分成一组,reduce对分好的那些组数据做累计计算。
hadoop是依据mapreduce的原理,用Java语言实现的分布式处理机制。
这个过程是高度并行的,意味着每个数据块都可以在一个单独的处理器上进行处理。这种并行处理是Hadoop MapReduce模型在处理大规模数据集时的关键优势之一。
hadoop原理:其最底部是 Hadoop Distributed File System(HDFS),它存储 Hadoop 集群中所有存储节点上的文件。HDFS的上一层是MapReduce 引擎,该引擎由 JobTrackers 和 TaskTrackers 组成。
到此,以上就是小编对于map的基本操作的问题就介绍到这了,希望介绍的几点解答对大家有用,有任何问题和不懂的,欢迎各位老师在评论区讨论,给我留言。
 微信扫一扫打赏
微信扫一扫打赏