本篇目录:
小波字典的构造方法
由一系列的短语或名词构成,其构成与 2 级字典的词条文件构成相同,主要包括点侧、岩性组合、成分前缀、颜色、岩性、岩石结构、岩石构造、矿物组成、矿化蚀变、产状、构造、样品、填图单位等。
当时人们研究图像的一种很普遍的方法是将图像在不同尺度下分解,并将结果进行比较,以取得有用的信息。Meyer正交小波基的提出,使得Mallat想到是否用正交小波基的多尺度特性将图像展开,以得到图像不同尺度间的“ 信息增量” 。
-图1")
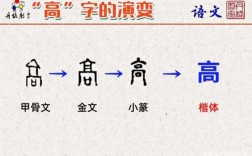
汉字的构造方法有种。一,象形。如:“月”字像一弯明月的形状,“龟”字像一只龟的侧面形状。二,形声。
提升格式是一种完全基于时域的双正交小波构造方法,与频谱分解方法相比,提升格式有固定的小波构造公式,其不仅简单易于理解,具有通用性和灵活性,而且有高效的小波变换实现方式。
查字典的正确步骤
1、用部首查字法。先查部首(如“艹”、“扌”、“亻”等),再查除部首该字剩下的笔画数。部首查字的方法:先分析,找出部首;再数清部首几画;然后在部首检录表中,按笔画数找到该部首。
2、查字典的方法:音序查字法、部首查字法、笔画查字法。音序查字法很多字典或词典是按汉语拼音字母的顺序编排的。
-图2")
3、查字典的方法主要有:部首查字法、音序查字法和数笔画查字法。音序查字法 运用音序查字法,要具备三个条件:字音要读得正确;准确无误地了解这个字的声母、韵母;掌握字母的写法。
4、查字典的四个步骤:确定要查的字的部首,先数一数这个部首有几画,再在“部首目录”里找到这个字的部首和页码。根据页码在“检字表”中找到这个部首。确定要查的字除去部首有几画。
5、音序查字法 先根据“汉语拼音音节索引”找到该字的声母,再到声母表中找寻对应的韵母,组合成一个音节,再根据提供的页码翻到字典的某一页,查到该汉字。比较麻烦。
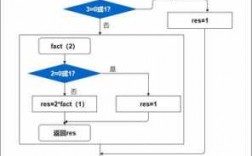
图解:数据结构与算法之字典树
字典树(Trie树)这一数据结构是不太常见但是十分好用typo id=typo-32 data-origin=而 ignoretag=true而/typo一种数据结构,博主也就是最近一段时间做了几道字节的题目才了解到字典树这一数据结构。
-图3")
数据结构中为了存储和查找的方便,用各种树结构来存储文件,我们首先介绍下基本的树的种类:二叉查找树(二叉排序树)、平衡二叉树(AVL树)、红黑树、B-树、B+树、字典树(trie树)、后缀树、广义后缀树。
字典树,是一种空间换时间的数据结构,又称Trie树、前缀树,是一种树形结构(字典树是一种数据结构),典型用于统计、排序、和保存大量字符串。二叉树是树形结构的一个重要类型。
按偏旁部首查字典
确定要查的字的部首。首先,你需要确定这个字的部首。部首是指将一个字按照不同的偏旁部分进行分类,例如木字旁、扌字旁等。这个目录会列出所有部首,按照它们的笔画数进行排列。找到该字在字典中的页码。
部首查字法方法如下:找出所查字的偏旁部首,数清部首笔画。在“部首检字表”的“部首目录”中找到这个部首,看清部首旁边标明的页码。按这个页码找到“检字表”中相应的那一项,并从这一页中找出要查的部首。
部首查字法的步骤:确定要查的字的部首,先数一数这个部首有几画,再在“部首目录”里找到这个字的部首和页码。根据页码在“检字表”中找到这个部首。确定要查的字除去部首有几画。
查字典偏旁如下:使用的是《新华字典》第11版。今天查一个“宝”字来演示。先找到部首检字表《部首目录》。查“宝”字,要先查宝盖头“宀”,按笔顺是三画,在三画部首里找到了宝盖头。
部首查字法步骤:找出所查字的偏旁部首,数清部首笔画。在“部首检字表”的“部首目录”中找到这个部首,看清部首旁边标明的页码。按这个页码找到“检字表”中相应的那一项,并从这一页中找出要查的部首。
稀疏分解中过完备原子库与gabor等字典是否是一个意思?
使用超完备的冗余函数字典作为基函数,字典的选择尽可能地符合被逼近信号的结构,字典中的元素被称为原子。
字典矩阵中所谓过完备性,指的是原子的个数远远大于信号y的长度(其长度很显然是n),即nk。MP算法(匹配追踪算法)1 算法描述 作为对信号进行稀疏分解的方法之一,将信号在完备字典库上进行分解。
FFT是离散傅氏变换的快速算法,它是根据离散傅氏变换的奇、偶、虚、实等特性,对离散傅立叶变换的算法进行改进获得的。它对傅氏变换的理论并没有新的发现,但是对于在计算机系统或者说数字系统中应用离散傅立叶变换。
到此,以上就是小编对于字典结构图的问题就介绍到这了,希望介绍的几点解答对大家有用,有任何问题和不懂的,欢迎各位老师在评论区讨论,给我留言。
 微信扫一扫打赏
微信扫一扫打赏