本篇目录:
数据库查询结果的动态排序
打开一个Access数据库软件,可以打开已创建好的数据库,使用表设计工具,创建一个表,如下图所示。接着,给创建的表格中输入数据,如下图所示。然后,鼠标左键选择【查询设计】按钮,如下图所示。
ORDER BY子句用于根据一个或多个列以升序或降序对数据进行排序。 默认情况下,一些数据库排序查询结果按升序排列。
-图1")
select top 20 * from url 就只选择20条当然快咯。
SQL的执行顺序先按照你的要求排序,然后才返回查询的内容。例如有一个名为ID自动增长的列,表中有100条数据,列的值得分别是49100。
select语句对对查询结果排序时,用order by子句指定排序字段,使用asc指定升序,使用desc降序。数据库select语句的排序查询方法:在select语句中,order by表示排序;asc表示升序;desc表示降序。
这个查询首先把结果按au_lname字段进行排序,然后按字段au_fname排序。
-图2")
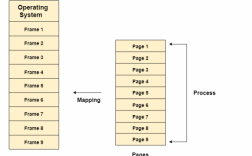
储存过程与其他编程语言中的过程类似,可以像使用函数一样重复调用判断...
存储过程可以设置参数,可以根据传入参数的不同重复使用同一个存储过程,从而高效的提高代码的优化率和可读性。
存储过程只在创造时进行编译,以后每次执行存储过程都不需再重新编译,而一般SQL语句每执行一次就编译一次,所以使用存储过程可提高数据库执行速度。
数据库存储过程的实质就是部署在数据库端的一组定义代码以及SQL。
Microsoft SQL Server 中的存储过程与其他编程语言中的过程类似,原因是存储过程可以:接受输入参数并以输出参数的格式向调用过程或批处理返回多个值。包含用于在数据库中执行操作(包括调用其他过程)的编程语句。
-图3")
存储过程:存储过程是 SQL 语句和可选控制流语句的预编译集合,以一个名称存储并作为一个单元处理。函数:是由一个或多个 SQL 语句组成的子程序,可用于封装代码以便重新使用。
存储过程如何使用
若我们在其实场景需要调用这个存储过程中的结果集,则不需要直接调用,而是将结果集先插入一个临时表即可。 create table #data ( Ftest1 int, Ftest2 int, Ftest3 int ) 注意:表定义的列数目要与存储过程的一致。
首先先创建一个存储过程,代码如图,存储过程主要的功能是为表JingYan插入新的数据。执行这几行代码,看到执行成功,数据库里现在已经有存储过程sp_JY。先看下JingYan表里目前的数组,如图,只有三行数据。
常用的系统存储过程的使用:(1)sp_helpdb 用于查看数据库名称和大小。(2)sp_helptext 用于显示规则、默认值、未加密的存储过程、用户定义函数、触发器或视图的文本。(3)sp_renamedb 用于重命名数据库。
首先编写存储过程的整体结构,如下图所示定义变量。定义变量后定义游标,begin,select sysdate into v_date from dual,end test_proc。
iihero on csdn)如何创建java存储过程?通常有三种方法来创建java存储过程。 使用oracle的sql语句来创建:e.g. 使用create or replace and compile java source named as 后边跟上java源程序。
到此,以上就是小编对于Sql存储过程的优缺点的问题就介绍到这了,希望介绍的几点解答对大家有用,有任何问题和不懂的,欢迎各位老师在评论区讨论,给我留言。
 微信扫一扫打赏
微信扫一扫打赏