本篇目录:
- 1、HDFS数据流
- 2、HDFS的文件存储过程?
- 3、HDFS文件
HDFS数据流
1、(1)客户端通过FileSystem.open()打开文件,相应地,在HDFS文件系统中DistributedFileSystem具体实现了FileSystem。
2、上半句话,访问文件不外乎读和写,需要读写时调用函数FileSystem&open()和FileSystem&create(),返回的对象是FSDataInputStream和FSDataOutputStream。 data直译成中文就是数据,stream直译成中文就是流。
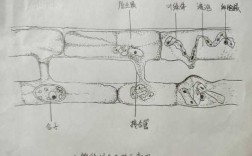
-图1")
3、前两步会返回一个FSDataInputStream对象,该对象会被封装成 DFSInputStream对象,DFSInputStream可以方便的管理datanode和namenode数据流。客户端调用read方法,DFSInputStream就会找出离客户端最近的datanode并连接datanode。
4、HDFS 最早是根据 GFS(Google File System)的论文概念模型来设计实现的,但是也有一些区别。
5、文件元数据在namenode上,文件读写操作首先被发往namenode,有namenode发送一个HTTP重定向至某个客户端,指示以流的方式传输文件数据的目的或源datanode。第二种方法依靠一个或多个独立代理服务器通过HTTP访问HDFS。
HDFS的文件存储过程?
1、(1) 如果保存请求来自集群内部,第一个副本放在发起者(应用)所在节点。
-图2")
2、hdfs的存储过程? ①client向hdfs发起写请求,通过RPC与namenode建立通讯。namenode检查文件是否存在等信息,返回是否可以存储。
3、(1)客户端通过FileSystem.open()打开文件,相应地,在HDFS文件系统中DistributedFileSystem具体实现了FileSystem。
4、HDFS的文件写入原理,主要包括以下几个步骤:namenode如何选择在哪个datanode 存储副本(replication)?这里需要对可靠性、写入带宽和读取带宽进行权衡。
5、HDFS中的文件是以数据块(Block)的形式存储的,默认最基本的存储单位是128 MB(Hadoop x为64 MB)的数据块。
-图3")
6、HDFS中的文件在物理上是分块存储(Block),快的大小可以通过配置参数(dfs.blcoksize)来规定,默认大小在Hadoopx中是128M,老版本中是64M。DataNode定期向NameNode 发送心跳报告 已告知自己的状态。
HDFS文件
1、HDFS(Hadoop分布式文件系统)是一种分布式文件系统,它主要用于存储大量的数据,并提供高可靠性和高吞吐量的数据访问。因此,HDFS是能够真正存储数据的分布式文件系统。
2、通过hdfsdfs-ls命令可以查看分布式文件系统中的文件,就像本地的ls命令一样。HDFS在客户端上提供了查询、新增和删除的指令,可以实现将分布在多台机器上的文件系统进行统一的管理。
3、在HDFS中,文件名以0或1开头的文件是非法的,因为Hadoop将它们视为隐藏文件。因此,不能在HDFS中创建文件名以0或1开头的文件。
4、当使用 Java API 操作 HDFS 时,可以使用 FileSystem.listFiles() 方法来获取文件列表。该方法接受一个 Path 对象,表示要列举文件的目录,并返回一个 RemoteIteratorLocatedFileStatus 对象,该对象可用于迭代目录中的文件。
5、向hdfs上传文件正确的shell命令是hdfsdfs-put。根据相关公开信息查询显示:向HDFS中上传任意文本文件,如果指定的文件在HDFS中已经存在,由用户指定是追加到原有文件末尾还是覆盖原有的文件。
到此,以上就是小编对于hdfs 写文件的问题就介绍到这了,希望介绍的几点解答对大家有用,有任何问题和不懂的,欢迎各位老师在评论区讨论,给我留言。
 微信扫一扫打赏
微信扫一扫打赏